When was the last time you read anything containing a significant amount of non-randomly generated numbers?
What if I told you that the first digits of those numbers follow a well defined frequency distribution, and that it would be possible to predict the frequency of every single leading digit $[1-9]$ with good accuracy?
Sounds quite far-fetched, doesn’t it? Well, this is exactly what I thought when I learned about Benford’s law , and that’s when I decided to actually verify it.
I wasn’t particularly interested in writing an introduction to Rust, as there are already many and well written resources out there . But, while I was writing the code to check the above statements, I realized how nicely this little project could work as a brief and practical introduction to the language, while also showing from a different angle why all the hype around it , and how does it actually feel to work with it.
And this was possible thanks to the fact that Benford’s law is an observation that can be very easily verified, and doing so allows us to touch not just different parts of the Rust language itself, but also many of the important tools that come with it.
Prerequisites
Ideally you have a background in software engineering, or you are currently studying computer science, and you are comfortable using the terminal. If this is the first programming language you are trying to learn, I would suggest to have a look at The Rust Book . You also ideally already have a basic knowledge of the Rust primitive and compound data types and keywords (reading the Rust Wikipedia article should give you all the information you need to be able to follow this post).
Content
The Benford law
From Wikipedia, Benford’s law states that:
In many naturally occurring collections of numbers, the leading digit is likely to be small.
and it goes even further by giving the exact probability of each leading digit1 that can be computed with the following formula:
$$p(digit) = log_{10} \left( 1 + \frac{1}{digit} \right)$$
Which can be nicely plotted as:
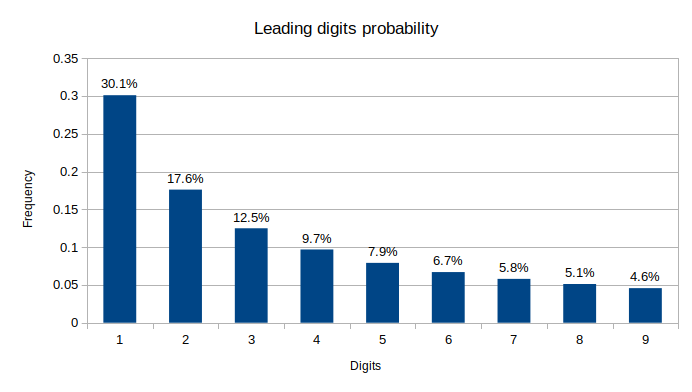
This means, for example, that more than 30% of your numbers will start with 1,
more than 17% will start with 2 and so on. It has been shown that these results
apply to a large variety of data sets, from population numbers, to stock prices,
to mathematical constants, and many others.
Now that we have enough context, we can start introducing Rust by writing a small command line application that, given a set of numbers, will compute the frequency of their leading digits, giving us the opportunity to verify how accurate Benford’s law is.
Chapter 00 - Installing Rust
The first thing to do is to install Rust .
Once we have installed Rust, we can check what is the version of the compiler:
$ rustc --version
rustc 1.47.0 (18bf6b4f0 2020-10-07)
If everything went well, we didn’t just install the Rust compiler, but we can now also use Cargo - The Rust package manager , which allows us to create, build, and run any project, as well as to download all the project’s dependencies.
You can find all the code of this post in the learn-rust-with-benford repository . The project there is organized in workspaces , so that you can run any of the following chapters with (for example) the following command for the first chapter:
$ cargo run --package chapter01
Chapter 01 - Setting up the Project
Let’s create a new project called benford:
$ cargo new benford
Cargo will create a new folder with the following structure:
benford
├── Cargo.toml
├── src
│ ├── main.rs
The Cargo.toml file, is a TOML
file, where we can specify our package
name and version, and the project’s external dependencies (currently none):
[package]
name = "benford"
version = "0.1.0"
authors = ["gliderkite <gliderkite@gmail.com>"]
edition = "2018"
[dependencies]
While main.rs is the source code file that contains the entry point of our
application:
fn main() {
println!("Hello, world!");
}
Where println! is just a function-like macro
that prints formatted
strings to the standard output.
Let’s compile and run the project for the first time; we can build it with
cargo build or simply build and run with cargo run2:
$ cargo run
Compiling benford v0.1.0
Finished dev [unoptimized + debuginfo] target(s) in 0.15s
Running `target/debug/benford`
Hello, world!
Another important command that we are going to use without mentioning throughout
the whole post is cargo fmt
: a tool for automatically formatting Rust
code according to style guidelines.
Chapter 02 - Reading the Dataset
For our little experiment, we need a set of real-life numbers, and I thought I could simply use the population census of my country, since it’s publicly available information, it’s not randomly generated data, it contains a relatively large set of numbers (in this example just above 8000), and it’s relatively simple to retrieve (you should try with the census of your own country and compare the results!).
This type of data is usually encoded in text files as tables, such as Excel spreadsheets, so it’s easy to export into CSV , and that is exactly the format we are going to use for our input. The content of the file (census.csv) looks like this:
City,Population
Agliè,2608
Airasca,3790
Ala di Stura,435
Albiano d'Ivrea,1847
Alice Superiore,694
Almese,6173
Alpette,267
Alpignano,16817
...
Where the first column is the name of the town, and the second (and last) column is its population (at the time of the census).
We could parse this text file by simply using filesystem and string utilities, but let’s instead introduce one of the most powerful tools we have at our disposal: dependencies management.
Most of the publicly available Rust packages (called crates) can be found on crates.io - The Rust crate registry , which is a large repository of all the packages different developers made available to the community, and it happens to contain the library we need to parse CSV files, which (surprise, surprise) was named csv .
To add a dependency to our project, we just need to add the dependency name, with
the version we chose, to our list of dependencies in the Cargo.toml file:
[dependencies]
csv = "1.1.3"
But how do we actually know what types and functions are provided by this library, and how do we use them? This is were docs.rs - The Rust documentation host comes to help, it’s the place where you can find all the documentation of all the packages hosted on crates.io , and we can start by having a look at the csv library documentation .
The first thing we want to do is probably learn how to read a CSV file by
using this library. If we look at the list of examples in the library
documentation, we can quickly find the example we need, which shows how the
csv::Reader::from_reader(reader: impl Read)
method creates a new CSV parser for the given reader:
let csv_reader = csv::Reader::from_reader(reader);
Notice how, even though Rust is a statically typed language, we didn’t have to
specify the type of csv_reader, since most of the times the compiler will
be able to infer the type
of the variables for us.
The argument reader needs to implement the Read trait
(traits are a
way to share behaviors between different types - often called interfaces in
other programming languages), which allows for reading bytes from a source.
In our case, the source will be the CSV file with the census data, which means we
need to create a new File object that implements the above mentioned Read
trait.
We can find this type in the Rust standard library that, among many other things,
also exports the types and functions that allow us to work with the filesystem, and,
as we have seen for the csv library, also comes with its own std documentation
,
where we can search and find the File type
we were looking for3.
Let’s proceed to create the CSV reader that is going to be used to read and iterate over the census data:
use std::fs;
fn main() {
let dataset = "census.csv";
println!("Reading dataset from {}", dataset);
let file = fs::File::open(dataset).expect("Cannot read dataset");
let reader = csv::Reader::from_reader(file);
}
and if we compile4 the project, we get:
$ cargo build
warning: unused variable: `reader`
--> src/main.rs:6:9
|
6 | let reader = csv::Reader::from_reader(file);
| ^^^^^^ help: if this is intentional, prefix it with an underscore: `_reader`
|
= note: `#[warn(unused_variables)]` on by default
You have now met the compiler, the reason why many Rust developers talk about pair programming when working with Rust: its warnings and error messages are extremely useful (and you will most likely encounter many thanks to the borrow checker 5).
One important thing to point out at this point is the .expect() method we used
when opening the file:
let file = fs::File::open(dataset).expect("Cannot read dataset");
The truth is that many operations can fail, and in Rust there are two main ways to handle errors:
- Calling the function-like macro
panic!when the error is not recoverable, which will print an error message (optionally showing the backtrace), unwind the stack, and terminate the program. - Return the outcome of an operation with the
Resultenum that either contains the outcome of a successful operation in itsOk(Type)variant, or it contains the information of the error, in itsErr(ErrorType)variant, which can be propagated and handled when most appropriate.
The easiest way to handle errors, especially when writing examples, is probably to
panic!, and this is exactly what our code does: if the file cannot be opened
for any reason, .expect() will simply call internally panic! with the given
error message and terminate the program, otherwise it will unwrap the content
of the Result::Ok(Type) variant (now stored in the variable file). This is
what happens for example if the census file doesn’t exist:
$ cargo run
thread 'main' panicked at 'Cannot read dataset: Os { code: 2, kind: NotFound, message: "No such file or directory" }', src/main.rs:5:40
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
We will come back to show how to handle recoverable errors with Result in a
following chapter.
Now that we have a CSV reader, we can use it to iterate over all the records/towns in the file, and extract from each record the value representing the population.
From the csv library documentation, we can see how to iterate over all the records
by using the csv::Reader::records()
method:
let reader = csv::Reader::from_reader(file);
println!("Parsing CSV records");
for record in reader.records() {
// record is a Result that we must unwrap before parsing its content
let record = record.expect("Invalid record");
println!("{:?}", record);
}
You can see how each record is actually wrapped in a
Result<csv::StringRecord, csv::Error> (since there may be records with invalid
format in the file).
For this reason, we need to unwrap it with .expect() to get its
csv::StringRecord if the record is valid, like we’ve done before when opening
the File (or panic! when it’s not valid and the Result contains an Error).
Notice also how the variable name record after the unwrapping is the same as
the one declared in the for loop. This is possible because Rust allows
variable shadowing
(in this particular case the outer variable declared in
the loop will be shadowed by the inner variable declared within it).
However, the above code will not compile; let’s see why by looking at the error message:
error[E0596]: cannot borrow `reader` as mutable, as it is not declared as mutable
--> src/main.rs:8:18
|
6 | let reader = csv::Reader::from_reader(file);
| ------ help: consider changing this to be mutable: `mut reader`
7 |
8 | for record in reader.records() {
| ^^^^^^ cannot borrow as mutable
As you can see, the reason why we cannot compile this code is because the method
we are trying to use (csv::Reader::records(&mut self)
) requires us to
mutably borrow our instance of Reader (this is what &mut self means - if
the method needed to immutably borrow, we would have found it written as &self),
and by default all declared variables in Rust are immutable.
As the compiler is suggesting, we simply need to declare the reader variable
mutable by adding mut in front of the variable name to fix our code:
let mut reader = csv::Reader::from_reader(file);
We can now iterate over all the towns, but what exactly are we printing when
using the macro println!("{:?}", record)?
This is another important feature of Rust that enables easier debugging by
automatically implementing the debug string representation of a type, when
deriving the Debug trait
. As a classic example, suppose you have a Point
structure with integer (32 bits) abscissa and ordinate fields:
struct Point {
x: i32,
y: i32,
}
let origin = Point { x: 0, y: 0 };
If you would like to print the value of your point to the standard output, the
only thing you need to do is to derive the Debug trait with a
procedural derive macro
, to be able to use the {:?} syntax:
#[derive(Debug)]
struct Point {
x: i32,
y: i32,
}
println!("{:?}", origin);
Point { x: 0, y: 0 }
And you can also enable pretty-printing with a slightly different syntax:
println!("{:#?}", origin);
Point {
x: 0,
y: 0,
}
Coming back to our example, we can finally start to see all the file records being printed to the standard output when we run the project:
$ cargo run
Parsing CSV records
StringRecord(["Agliè", "2608"])
StringRecord(["Airasca", "3790"])
StringRecord(["Ala di Stura", "435"])
StringRecord(["Albiano d\'Ivrea", "1847"])
StringRecord(["Alice Superiore", "694"])
StringRecord(["Almese", "6173"])
StringRecord(["Alpette", "267"])
StringRecord(["Alpignano", "16817"])
...
Chapter 03 - Logging
We ended the second chapter by printing all the cities in the census file to the standard output, and that is quite a lot of output. Let’s see if we can better handle the information we decide to display to stdout.
Usually, we have to deal with different kinds of information, and each information could be associated to how important it is and therefore in what situations we want to display it. This is where logging can help, even when just redirecting output to stdout.
What we need is a logging facade (that offers an abstraction to the
logging APIs we are going to use) and an implementation. These can be found
respectively in the log crate
and in the env_logger crate
(but
there are several other implementations that you are free to try out).
As we have done for the csv library, the first thing to do is to import them
as new dependencies in our Cargo.toml file:
[dependencies]
csv = "1.1.3"
env_logger = "0.8.1"
log = "0.4.11"
Using a logger is relatively simple, we just need to initialize the logger implementation and then use the various log APIs provided by the facade according to the level we need (trace, debug, info, warn, or error):
fn main() {
// initialize the logger implementation
env_logger::init();
let dataset = "census.csv";
log::info!("Reading dataset from {}", dataset);
let file = fs::File::open(dataset).expect("Cannot read dataset");
let mut reader = csv::Reader::from_reader(file);
log::info!("Parsing CSV records");
for record in reader.records() {
let record = record.expect("Invalid record");
log::trace!("{:?}", record);
}
}
As you can see, we have just replaced the println! macros with log::info! or
log::trace! macros according to the level of logging we find the most
appropriate. And we can enable different level of logging by setting the
environment variable RUST_LOG, for example:
$ RUST_LOG=info cargo run
[2020-10-04T12:17:45Z INFO benford] Reading dataset from census.csv
[2020-10-04T12:17:45Z INFO benford] Parsing CSV records
While setting RUST_LOG=trace would also print all the file records.
Chapter 04 - Parsing the Dataset
The next step involves extracting the information we need from each record (i.e. the population value) and building the frequency map of the leading digits.
As we have seen, iterating over the file records yields a list of
csv::StringRecords
, and we need to extract the population value, which
corresponds to the second column of our dataset. We can achieve this by using
the csv::StringRecord::get()
method:
for record in reader.records() {
let record = record.expect("Invalid record");
let city = record.get(0);
let population = record.get(1);
log::trace!("{:?} population: {:?}", city, population);
}
And if we run the project, we’ll see something similar to:
$ RUST_LOG=trace cargo run
[INFO] Reading dataset from census.csv
[INFO] Parsing CSV records
[TRACE] Some("Agliè") population: Some("2608")
[TRACE] Some("Airasca") population: Some("3790")
...
From this output, it looks like we are not just dealing with strings; in fact, as
you can see, these are wrapped in a type which Debug representation is, for
example, Some("Airasca") or Some("3790").
You are now meeting what is, with Result, possibly the most important enum in
Rust: Option
. The Option type, as the name suggests,
represents an optional type, and it can be either Some(Type) or None, and
the Rust type system allows us to know at compile time whether the option can be
unwrapped while safely getting its content, or if instead it does not contain
anything. And this feature helps to prevent a class of bugs that in other languages
is related to the billion dollar mistake
(where the type system includes
null references or null pointers).
In order to use an Option, we can introduce another important feature of Rust:
pattern matching
. Basically, what we need is to match the value of the
Option that represents the city population with a pattern that can be either
Some(population) when the CSV record contains a second column, or None when
it doesn’t (which should never happen if our input is correct). To do so, we can
use the Rust keyword match:
for record in reader.records() {
let record = record.expect("Invalid record");
match record.get(1) {
Some(population) => log::trace!("Population: {}", population),
None => log::warn!("No population value!"),
};
}
$ RUST_LOG=trace cargo run
[INFO] Reading dataset from census.csv
[INFO] Parsing CSV records
[TRACE] Population: 2608
[TRACE] Population: 3790
...
We can now finally build the frequency map, where the keys of the map will be all the possible digits $[1-9]$, while the values will be the frequency these digits appear as the first digit of the population values.
The only choice we need to make is if we want to deal with these numbers as actual integers or keep them as they are currently represented as strings. Either choice is fine for the sake of this tutorial, so we are going to continue with the strings we currently have, to avoid the conversions (but you are free to try changing the code using integers instead).
Dealing with strings in Rust is not straightforward , and this is essentially because dealing with strings in general is not straightforward; it just happens that many other programming languages made the choice of hiding this complexity from the user. Fortunately, what we need to do is not too complex: we need to get the first digit of the population value, that is (being the population value a string), we need to extract its first character.
If we try with:
let digit = population[0];
We would just get the following error:
--> src/main.rs:20:29
|
20 | let digit = population[0];
| ^^^^^^^^^^^^^ string indices are ranges of `usize`
|
= help: the trait `std::slice::SliceIndex<str>` is not implemented for `{integer}`
= note: you can use `.chars().nth()` or `.bytes().nth()`
see chapter in The Book <https://doc.rust-lang.org/book/ch08-02-strings.html#indexing-into-strings>
= note: required because of the requirements on the impl of `std::ops::Index<{integer}>` for `str`
Fortunately the error message is very helpful; it shows a link to the Rust book with a nice explanation on why indexing strings is not possible, but also a couple of solutions that we can use to fix this problem. There is also a third option, which is semantically equivalent, and that’s what we are going to use:
// get the first character of the population (represented as string)
let digit = population.chars().next();
If you look closely
, you’ll see that digit is not exactly a character, but
it’s a character wrapped in an Option, since the population may be an empty
string and the first character may not even exist, and therefore we are forced
to deal with this scenario as we did previously with the population record.
But our loop logic is starting to become more difficult to follow, and it would get worse if we started adding another pattern matching. Maybe we could extract part of the logic into a separate function that, given an immutable reference to a valid record, would optionally return the first digit of the population value as character.
This is what a possible implementation could look like:
fn get_first_digit(record: &csv::StringRecord) -> Option<char> {
log::trace!("Parsing record: {:?}", record);
match record.get(1) {
Some(population) => population.chars().next(),
None => None,
}
}
If you notice, we only return Some(char) when we both have a population in the
record and the population contains a first character (in any other case this
function will return None). We can try to improve this implementation, and if
you read the Option documentation
you will notice there are several
utility methods we could use to make the implementation less verbose by replacing
the pattern matching with the semantically equivalent Option::and_then
combinator:
record
.get(1)
.and_then(|population| population.chars().next())
If you are wondering about the syntax inside the and_then combinator, this is
how you define closures
in Rust, which are basically anonymous functions
that can capture the environment. And in this case, the closure accepts a string
as the only input (the population) and returns an Option that wraps a
character.
But how do we know that the character we are returning, when the Option contains
Some(char), will actually be a valid digit between 1 and 9? If our population
record contains invalid data, such as abc-xyz, this method would return the
character a.
To solve this issue, we can simply chain another Option combinator, to filter
only valid characters:
record
.get(1)
.and_then(|population| population.chars().next())
.filter(|c| c.is_ascii_digit() && *c != '0')
As you can see in the last step, we use the Option::filter
method to
keep every character that is an ASCII digit $[0-9]$, but since our numbers can
only start with $[1-9]$ we need to take that into account and remove any possible
string starting with the character '0'. If these conditions are not satisfied,
our new function will simply return None, as if no digit was found for the
given record.
If you find the syntax *c != '0' odd, you just need to know that the filter
closure input c is a reference to a character, and therefore it needs to be
dereferenced
before being compared to another character.
Now we can match the Option returned by this function in our loop, and we can
do so by introducing an alternative but equivalent syntax to match:
for record in reader.records() {
let record = record.expect("Invalid record");
if let Some(digit) = get_first_digit(&record) {
log::trace!("Found digit '{}' in {:?}", digit, record);
} else {
log::warn!("No valid digit found in {:?}", record);
}
}
$ RUST_LOG=trace cargo run
[INFO] Reading dataset from census.csv
[INFO] Parsing CSV records
[TRACE] Parsing record: StringRecord(["Agliè", "2608"])
[TRACE] Found digit '2' in StringRecord(["Agliè", "2608"])
[TRACE] Parsing record: StringRecord(["Airasca", "3790"])
[TRACE] Found digit '3' in StringRecord(["Airasca", "3790"])
...
The only missing part is to create the frequency map according to the digits found.
What we need is an associative array; for that, the obvious choice would
be a hash table
since it would have ideal time complexity, and we can
find a hash table implementation in the Rust standard library under the
HashMap type
. The keys of our map will be the digits $[1-9]$ as we
parse them (i.e. as characters), while the values will be integer values that
correspond to how many times we found that leading digit in the records.
We can now proceed and fill up the frequency map:
use std::collections::HashMap;
let mut frequency = HashMap::new();
for record in reader.records() {
let record = record.expect("Invalid record");
if let Some(digit) = get_first_digit(record) {
// find the value corresponding to the digit key or insert a new
// entry with an initial value of 0
let count = frequency.entry(digit).or_insert(0);
// count is a mutable reference to the value in the HashMap
// increment its value by 1 after dereferencing it
*count += 1;
}
}
log::debug!("Frequency: {:?}", frequency);
As you can see, we were able to skip the initialization of the HashMap (that
could have been initialized with all zeros values for each key digit - as to
represent and empty census file), and rely on our get_first_digit function, which
returns Some(digit) only if the parsed record is valid.
Once we have a valid digit, we query the frequency map to get the current value
representing how many times we already encountered it, and increment its
value (count) by 1.
If the digit we are trying to use as key doesn’t belong yet to the frequency map,
a new entry will be created with an initial value equal to 0.
$ RUST_LOG=debug cargo run
[INFO] Reading dataset from census.csv
[INFO] Parsing CSV records
[DEBUG] Frequency: {'2': 1395, '7': 455, '4': 745, '1': 2486, '9': 362, '8': 449, '6': 550, '3': 1007, '5': 643}
Are these values starting to look familiar?
Chapter 05 - Comparing Results
We ended the previous chapter with a frequency map of our digits that looks like this:
Frequency: {
'2': 1395,
'3': 1007,
'5': 643,
'6': 550,
'4': 745,
'8': 449,
'9': 362,
'1': 2486,
'7': 455,
}
But these are just the raw frequencies of the first digits; what we would like
is instead the percentages in which these digits appear and, ideally, they would be
sorted by digit from 1 to 9. There are many ways to achieve this; one way is
to store our final results into a different data structure where keys are
sorted: in Rust, you can find this data structure under the BTreeMap type
.
The keys of the new map are always going to be all the (sorted) digits $[1-9]$ as characters, while the values will be floating point numbers representing the percentage of how often they appear.
let total: usize = frequency.values().sum();
let percentage: BTreeMap<char, f32> = frequency
.into_iter()
.map(|(digit, count)| (digit, count as f32 / total as f32))
.collect();
log::info!("Percentage: {:#.2?}", percentage);
What happens in the above code is that, after we compute the sum of all the
frequency values (i.e. how many total digits we encountered), we create a new
BTreeMap by iterating over all the key-value pairs of our frequency map and,
for each of these, we keep the digit as is while the value count is mapped to
its respective percentage, to then finally collect all the new key-value pairs
into the new data structure.
And, believe it or not, this is what we get:
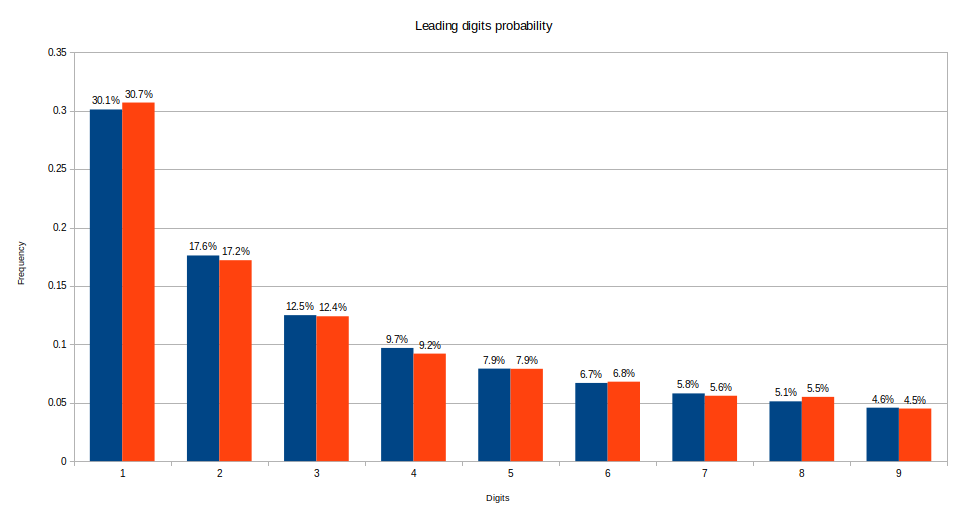
Percentage: {
'1': 0.31,
'2': 0.17,
'3': 0.12,
'4': 0.09,
'5': 0.08,
'6': 0.07,
'7': 0.06,
'8': 0.06,
'9': 0.04,
}
Let’s compare it with the expected values (the blue bars represent the expected values, while the red ones represent the results we got from the census file):
Chapter 06 - Error Handling
In Chapter 02 , we saw how we decided to simply terminate the program in some of the cases where we could encounter an error, independently if we could actually recover from it or not.
There may be situations in which terminating the whole program is a valid
solution; for example, when the census file doesn’t exist, there is
very little we can do. We can consider the existence of the input file as an
invariant that must hold no matter what, and if it doesn’t, there is no point
for our program to run. In such situations, panic! is a valid compromise.
Nevertheless, we should try to recover whenever possible and, depending on our logic, we can try to implement a different mechanism for error handling that would fit better the expectations of our application.
For example, let’s consider what happens when we have managed to open the file, but we can’t parse a specific record:
// record is a Result that we must unwrap before parsing its content
let record = record.expect("Invalid record");
With our current implementation, if the record is not valid, the program will terminate. Let’s assume instead that discarding an invalid record is a valid choice.
A first way to check whether the record is valid or not is to use pattern matching, as we’ve seen before for similar situations. If you remember, record is a
Result enum
before we unwrap it with .expect(), this means that we can
pattern match it with its variants to write a semantically equivalent version of
our code:
let record = match record {
Ok(record) => record,
Err(e) => panic!("Invalid record: {:?}", e),
};
And if our census file contained, for example, an invalid second record such as:
City,Population
Agliè,2608,
Airasca,3790, UNEXPECTED
Ala di Stura,435
...
Our program would panic! with the following error message:
[INFO] Parsing CSV records
thread 'main' panicked at 'Invalid record: Error(UnequalLengths { pos: Some(Position { byte: 16, line: 2, record: 1 }), expected_len: 2, len: 3 })', src/main.rs:26:23
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Let’s just skip to the next record if the one we are currently at is not valid:
let record = match record {
Ok(record) => record,
Err(e) => {
log::warn!("Skipping invalid record: {:?}", e);
continue;
}
};
And we could even exploit the same combinator techniques we’ve seen before, to
make the implementation a bit less verbose, thanks to the fact that
reader.records() returns an object that implements the Iterator trait
,
a very powerful abstraction that offers a large set of useful methods.
And similarly to what we have done to filter valid characters with the Option
type, here we can use the Iterator::filter_map()
method in combination
with Result::ok()
to filter for valid records:
for record in reader.records().filter_map(Result::ok) {
// parse valid record
}
Chapter 07 - Command Line Arguments
For our last chapter, let’s improve our program so that we get rid of the hardcoded census file path, and see how we can get an arbitrary path as a new command line argument.
There are several Rust crates that allow us to build command line applications, capable of parsing complex command line arguments while providing useful and well presented information to the user (as an example, you should try to implement this last chapter by using clap or structopt ). But our case is very simple, we just need to parse a single and not optional argument, and bringing a new dependency wouldn’t be justifiable6.
To do that, the standard library already offers all we need with the
std::env::args function
, which returns the arguments that our program was
started with. This method also returns an object that implements Iterator, and
therefore we can use any of the methods that the Iterator trait offers.
We are interested in the first user specified command line argument that will
contain the full path of the census file, which means that when parsing the
command line arguments, we need to skip the first one (the path of our binary).
Fortunately, we have partially seen how to do this already with the
Iterator::nth() method
that returns an Option with Some(Type) if the
item in position nth exists (otherwise returns None):
use std::env;
let dataset = match env::args().nth(1) {
Some(path) => path,
_ => panic!("The path of the census file must be specified"),
};
As a final note, the underscore _ you see in the above match is an identifier
that can be used to match anything else (i.e. any other possible enum variant),
which, in the case of a Option enum, is equivalent to writing None.
To run your new implementation, you can pass a command line argument to your binary via Cargo with:
$ cargo run -- census.csv
Conclusions
We’ve covered a lot together, and obviously there would be a lot more to cover (for that I suggest to have a look at the Rust Book ), but in the end we’ve managed to complete a nice implementation to show the weirdness of Benford’s law in less than 50 lines of code.
I leave you with the full code, so that you can have a single place where to review everything we’ve seen so far.
use std::{
collections::{BTreeMap, HashMap},
env, fs,
};
fn main() {
env_logger::init();
let dataset = match env::args().nth(1) {
Some(path) => path,
_ => panic!("The path of the census file must be specified"),
};
log::info!("Reading dataset from {}", dataset);
let file = fs::File::open(dataset).expect("Cannot read dataset");
let mut reader = csv::Reader::from_reader(file);
let mut frequency = HashMap::new();
log::info!("Parsing CSV records");
for record in reader.records().filter_map(Result::ok) {
if let Some(digit) = get_first_digit(&record) {
log::trace!("Found digit '{}' in {:?}", digit, record);
let count = frequency.entry(digit).or_insert(0);
*count += 1;
} else {
log::warn!("No valid digit found in {:?}", record);
}
}
log::debug!("Frequency: {:?}", frequency);
let total: usize = frequency.values().sum();
let percentage: BTreeMap<char, f32> = frequency
.into_iter()
.map(|(digit, count)| (digit, count as f32 / total as f32))
.collect();
log::info!("Percentage: {:#.2?}", percentage);
}
fn get_first_digit(record: &csv::StringRecord) -> Option<char> {
log::trace!("Parsing record: {:?}", record);
record
.get(1)
.and_then(|population| population.chars().next())
.filter(|c| c.is_ascii_digit() && *c != '0')
}
As possible follow-up exercises, you can fork the learn-rust-with-benford repository and try to implement any of the following options:
- In Chapter 02 , I showed you the format (CSV) and the scheme (2 columns) of the census file used throughout the whole post. If you decided to use the census of your own country, you may have to deal with a different scheme or a different format. Try to modify the program when having to deal with such differences.
- In Chapter 03
, we used the
env_loggercrate as our logger implementation. Try to find in crates.io other possible crates that you could use to replace it. - In Chapter 04
, we decided to deal with
strings and use the
chartype for our digit. Try to modify the program using integers instead. - In Chapter 05
, we used a
BTreeMapto both sort our digits and store the final percentage values. Can you think of and implement other ways to achieve the same result? - In Chapter 06 , we decided to simply skip any invalid record when iterating over the full set of records. What if we also wanted to log when a record is not valid and compute the percentage of how many invalid records were found?
- In Chapter 07 , we used the function provided by the standard library to parse the command line arguments. There are several crates that allow the same while giving you the option to display detailed information to the user. Can you modify the program to make use of any of the available alternatives?
-
Please note that the reason why this law seems to yield such accurate results is, although quite interesting, out of the scope of this post. ↩︎
-
By default
cargo buildwill compile your project in Debug mode (dev profile), you can enable optimizations and compile it in Release withcargo build --release. You can go even further and customize your builds with specific profile settings in yourCargo.toml. ↩︎ -
If you want to know what are the traits that are implemented for a specific type, just look for the
Trait Implementationssection in the type documentation. ↩︎ -
When the size of your project increases, the Rust compiler starts to become slower and slower; if you just need to check whether your code is correct without actually producing an executable you can use
cargo checkinstead of usingcargo build, or (if you want even more useful suggestions from the compiler) try using clippy withcargo clippy. ↩︎ -
The borrow checker is out of the scope of this post; for now you just need to know that is thanks to the borrow checker that the Rust compiler can prevent data races (and consequent undefined behavior ) at compile time. ↩︎
-
Dependency management is very, very hard . ↩︎